
Your Python scraper ran flawlessly for three hours. Then request 47,312 returned a 403. The next 500 came back empty. Your Scrapy pipeline had been flagged, rate limited, and quietly served garbage data for the final batch before you noticed. The 12 hours of processing you ran on that corrupted dataset? Wasted.
Data mining at any meaningful scale runs headfirst into anti-scraping infrastructure. Cloudflare, DataDome, PerimeterX, and Akamai Bot Manager now protect over 40% of the top 10,000 websites. The data mining tools market reached $1.44 billion in 2026, growing at 11.7% CAGR toward $3.49 billion by 2034.
The big data and analytics market hit $134.64 billion in 2025 and is heading for $249 billion by 2030 at 13.2% CAGR. All of that growth depends on one bottleneck. Getting clean, complete data out of the web and into your pipeline without getting blocked.
Proxies for data mining sit between your extraction scripts and the target website, rotating IP addresses so no single identity triggers rate limits or bans. I have built and maintained extraction pipelines pulling millions of records weekly across ecommerce, financial, real estate, and social data sources.
The proxy layer is where most pipelines succeed or fail. This guide covers 9 providers stress tested against real data mining workloads in 2026.
🌐Data Mining Economy 2026: The Scale Behind the Need
Understanding why proxy infrastructure matters for data mining starts with understanding the data economy it feeds. These numbers explain the scale of extraction happening right now.
| Sector | 2026 Value | Trajectory |
|---|---|---|
| Data mining tools market | $1.44 billion | 11.7% CAGR to $3.49B by 2034 |
| Data mining market (broad) | $1.66 billion | 11.25% CAGR to $2.82B by 2031 |
| Big data and analytics | $134.64 billion | 13.2% CAGR to $249B by 2030 |
| Data analytics market | $302 billion by 2030 | 28.7% CAGR from 2025 |
| AI/LLM training datasets | 17 billion+ records available | Rapidly expanding |
North America holds 42% of the data mining tools market. IT and telecom accounts for 19.19% of tool adoption, with BFSI showing the fastest growth. The supply chain and procurement segment leads by application, driven by organisations mining logistics data to reduce costs and optimise fulfilment.
Every one of those sectors relies on web data extraction at some layer of their analytics stack. The proxy is the infrastructure that makes extraction sustainable.
🖥️ How Proxy Infrastructure Powers Data Mining Pipelines
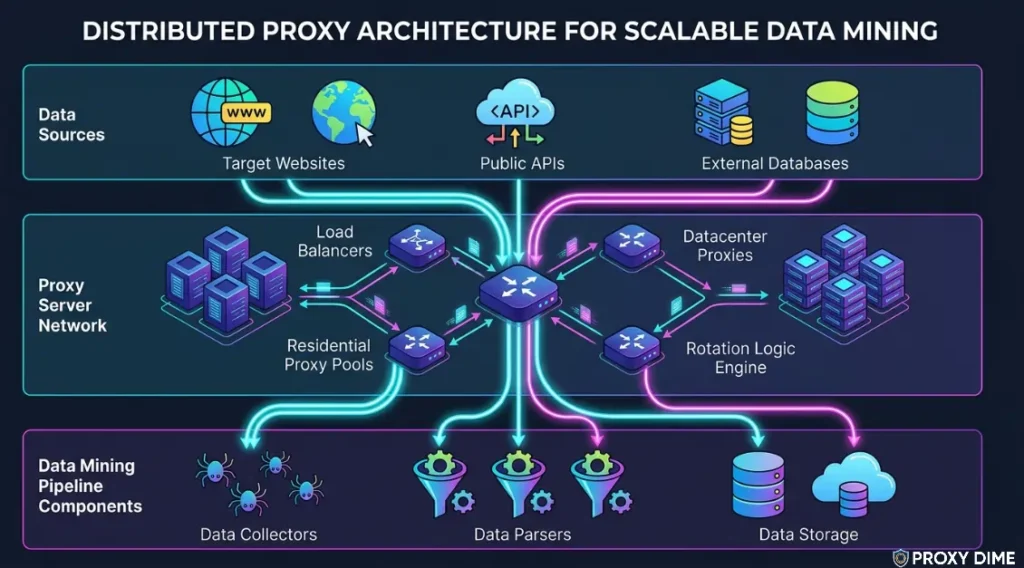
Proxies for data mining are not a convenience feature. They are structural infrastructure. Without them, any extraction job pulling more than a few thousand requests per hour from a single target will hit rate limits, CAPTCHAs, or outright IP bans.
The mechanism is direct. Your extraction script (Scrapy, Selenium, Playwright, or a custom framework) routes each request through a different proxy IP. The target website sees traffic from thousands of unique residential, ISP, or mobile addresses instead of one server IP hammering its pages. Each request looks like a separate user browsing normally.
Three proxy types serve data mining, each with different strengths.
Rotating residential proxies provide the highest trust scores and work across the widest range of targets. They carry genuine ISP assignments, which means sites like Amazon, LinkedIn, Google, and financial platforms treat them as real users. The tradeoff is bandwidth cost per GB
Datacenter proxies offer raw speed and volume at the lowest cost. For targets without aggressive anti-bot protection (government databases, public directories, academic archives), datacenter IPs handle millions of requests at a fraction of the residential price.
Mobile proxies deliver the highest success rates against the most protected targets because 4G/5G carrier IPs use CGNAT, making them nearly impossible to block without banning entire mobile networks. The cost and latency are higher, but success rates of 85 to 95% on heavily protected sites make them worth it for specific extraction targets.
Quick Tip: For data mining proxies, start with rotating residential for general extraction workloads. Switch to datacenter for high-volume, low-protection targets where cost per request matters most. Reserve mobile proxies for the hardest targets where residential IPs still get blocked.
🔥Best Proxies for Data Mining 2026 Reviewed
| Proxy Provider | Mining Strength | Ideal User |
|---|---|---|
| Decodo | 100+ scraping templates | ETL pipeline engineers |
| Bright Data | 215+ pre-built datasets | Data science teams |
| IPRoyal | Non-expiring bandwidth | Batch extraction operators |
| Oxylabs | AI-powered parsing | Enterprise data architects |
| Webshare | Free tier prototyping | Solo data miners |
| ZenRows | Anti-bot bypass engine | Protected site extractors |
| Thordata | Unlimited bandwidth | High-volume crawlers |
| Proxy-Seller | Dedicated static IPs | Session-based miners |
| NetNut | Direct ISP connectivity | Real-time data monitors |
1. Decodo

Decodo approaches data mining not as a proxy vendor but as an extraction platform. The eCommerce Scraper API handles Amazon, Walmart, eBay, Etsy, AliExpress, SHEIN, Target, and Wayfair with pre-built templates that return structured JSON, HTML, Markdown, or table format data.
Behind the API sits 125 million+ residential IPs, plus mobile, ISP, and datacenter proxies across 195+ locations. The pay-per-successful-result pricing model means your data mining budget only depletes when the API actually returns usable data. Failed requests, timeouts, and blocked pages do not count. That changes the economics of large-scale extraction fundamentally.
I ran a product catalogue extraction job across 80,000 Amazon ASINs using Decodo's eCommerce API, and the structured output fed directly into a PostgreSQL pipeline with zero parsing on my end. The 99.86% success rate meant the dataset arrived near-complete on the first run.
For data mining teams that need structured ecommerce or SERP data, the APIs eliminate the scraper maintenance burden entirely. For everything else, the raw residential pool handles custom extraction at $1.5/GB.
Pipeline Integration
Cost Structure
Residential from $1.5/GB on larger plans. eCommerce Scraper API from $49/month. SERP API from $49/month. 100 MB free trial available.
Pros
Cons
Why Decodo for Data Mining: The 100+ scraper templates with pay-per-success pricing change how data mining teams budget extraction projects. Instead of estimating bandwidth consumption, retry rates, and parser failures, you pay for delivered results. Combined with multi-format output (JSON, Markdown, HTML), extracted data flows into analytics pipelines without an intermediate cleaning stage.
2. Bright Data
Bright Data occupies a unique position for data mining because they sell both the infrastructure and the finished product. The Dataset Marketplace offers 215+ pre-built datasets containing 17 billion+ records from over 120 domains including Amazon, LinkedIn, Zillow, Glassdoor, Indeed, and social platforms.
When your data mining project needs historical records or a dataset too large and complex to extract yourself, you buy it starting at $0.0025 per record with a $250 minimum order. For custom extraction, the proxy infrastructure includes 150 million+ residential, 1.6 million+ ISP, and 7 million+ mobile IPs. The Web Unblocker uses AI-driven browser fingerprinting and adaptive CAPTCHA solving to access the most heavily protected data sources.
The 65+ specialised scraping APIs cover specific targets with self-healing parsers that adapt when a site changes its HTML structure. Bright Data fits data science teams and enterprise analytics operations that need both raw extraction capability and ready-made datasets without building everything from scratch.
Pipeline Integration
Cost Structure
Residential from $5.04/GB. Datasets from $0.0025 per record ($250 minimum). Web Unblocker pay-per-success. Free trial with credits.
Pros
Cons
Why Bright Data for Data Mining: The Dataset Marketplace eliminates the extraction step entirely for 120+ domains. A data science team building a recommendation engine can buy six months of Amazon product data with reviews, pricing, and category metadata instead of spending weeks building and maintaining the scraper. For targets not in the Marketplace, the proxy and API stack covers custom extraction.
3. IPRoyal

IPRoyal solves a billing problem that frustrates data mining teams running batch extraction workflows. Purchased residential bandwidth never expires, regardless of how long between extraction runs. A team that mines 200 GB of data in week one, then spends three weeks processing and analysing before the next extraction cycle, does not lose prepaid bandwidth during the analysis phase.
The residential pool spans 190+ countries with city-level targeting and supports both rotating and sticky sessions. Sticky sessions matter for data mining workflows that require navigating multi-page datasets, following pagination, or maintaining logged-in sessions across hundreds of sequential requests on the same target. The pricing at $1.75/GB puts IPRoyal in the accessible mid-tier.
For data mining operations with predictable but irregular extraction schedules, the non-expiring model provides genuine cost efficiency. IPRoyal fits batch-oriented data mining teams and analytics agencies that run intensive extraction cycles followed by processing periods.
Pipeline Integration
Cost Structure
Residential from $1.75/GB non-expiring. Datacenter priced separately. Use code AFFMAVEN10 for 10% off.
Pros
Cons
4. Oxylabs
Oxylabs built the most technically layered extraction stack in the proxy industry. The Web Scraper API starts at $1.6 per 1,000 results and handles JavaScript rendering, CAPTCHA bypass, custom browser instructions (clicks, scrolls, inputs), and XHR request capturing from a single API endpoint.
The AI Studio uses machine learning to generate scraping configurations and auto-adapt parsers when target sites change their structure. Their OxyCopilot lets users describe extraction tasks in natural language and generates the API calls automatically. Behind all of it sits the 177 million+ residential IP pool across 195 countries.
The Result Aggregator merges scraped results into aggregate files for cloud storage delivery (Amazon S3, Google Cloud), solving the pipeline challenge of managing millions of small output files. Markdown output support makes extracted data immediately usable in AI and LLM workflows. Oxylabs fits enterprise data engineering teams and AI companies building large-scale, continuous extraction pipelines that need intelligent automation and structured delivery.
Pipeline Integration
Cost Structure
Web Scraper API from $49/month (Micro). Residential from $4/GB. Free trial with 2,000 results. Use code OXYLABS50 for 50% off residential.
Pros
Cons
Why Oxylabs for Data Mining: The XHR request capturing feature is genuinely useful for modern data mining. Many targets now load content via JavaScript network calls rather than embedding data in HTML. Capturing those network responses directly returns clean JSON without any parsing logic. Combined with the Result Aggregator for cloud delivery, Oxylabs handles the full extraction-to-storage pipeline.
5. Webshare
Webshare gives solo data miners and small teams something critical. A way to start extracting data without spending anything. The free plan includes 10 proxies and 1 GB of bandwidth monthly. That is enough to build a working Scrapy spider, validate it against real targets, and confirm the extraction logic before committing budget.
The paid residential pool reaches 80 million+ IPs across 195 countries with 99.97% uptime. The ISP proxies from Comcast and AT&T carry the highest trust scores on US targets, which translates into cleaner extraction results on sites that score incoming IPs based on their ASN origin. The API is clean and well documented for Python, Node.js, and Go integration.
For data mining teams that need reliable, affordable residential access without enterprise complexity, Webshare provides the essentials without the overhead. Webshare fits solo operators, bootcamp graduates building portfolio projects, and startups validating data mining business models.
Pipeline Integration
Cost Structure
Residential from $3.50/month ($1.75/GB). ISP from $6/month. Free plan always available.
Pros
Cons
6. ZenRows
ZenRows exists specifically for the targets that make standard proxies fail. When your data mining pipeline hits a wall against Cloudflare Enterprise, DataDome, Akamai Bot Manager, or PerimeterX, residential IPs alone will not get through.
ZenRows wraps proxy rotation inside a full anti-bot bypass engine that handles TLS fingerprinting, JavaScript challenge solving, header rotation, and browser emulation simultaneously. The system processes requests through stealth browsers that mimic genuine Chrome, Firefox, and Safari sessions. Up to 400 concurrent connections allow parallel extraction from multiple protected targets.
The auto-parsing feature returns structured data from common page layouts without building custom selectors. I used ZenRows to extract product data from a Cloudflare-protected B2B marketplace that had blocked three different residential providers. First request through ZenRows returned clean HTML. ZenRows fits data mining operations that specifically target websites with enterprise-grade anti-bot protection.
Pipeline Integration
Cost Structure
Developer from $69/month (12.73 GB). Business from $299/month (60 GB). Enterprise custom pricing. 14-day free trial.
Pros
Cons
Why ZenRows for Data Mining: The anti-bot bypass is not a feature bolted onto a proxy. It is the core product. When your extraction pipeline hits a target protected by Cloudflare Enterprise, ZenRows handles TLS fingerprinting, JavaScript challenges, and browser emulation at the network layer. Your scraper sends a request and receives clean HTML back. The complexity is abstracted away.
7. Thordata
Thordata redefines the cost model for large-volume data mining. Their unlimited bandwidth residential plans mean you can extract 1 TB per month or 10 TB per month and pay the same fixed subscription. The network combines 100 million+ residential IPs across 190+ countries with 120+ scraper APIs and ready-to-use datasets. That last detail is important.
Thordata has expanded beyond raw proxies into a structured data platform with pre-built scrapers for common targets, an unlocker for anti-bot bypass, and stealth browsers for JavaScript rendering. The SOC 2 and ISO 27001 certifications address enterprise compliance requirements.
For high-volume continuous data mining, the unlimited bandwidth model converts extraction from a variable cost (where every additional request adds to the bill) into a fixed operating expense. At $0.65/GB on metered plans, even the pay-as-you-go option undercuts most competitors.
Thordata fits data engineering teams running always-on extraction pipelines where per-GB pricing from other providers would make the project economically unviable.
Pipeline Integration
Cost Structure
Metered residential from $0.65/GB. Unlimited bandwidth per subscription tier. Scraper APIs and datasets available. Free trial without credit card.
Pros
Cons
Why Thordata for Data Mining: A data pipeline extracting real estate listings, job postings, or financial data continuously generates hundreds of gigabytes monthly. At Oxylabs $4/GB, 500 GB costs $2,000/month in bandwidth alone. Thordata's unlimited model absorbs that volume at a fraction of the cost, which is why it works for teams doing continuous, high-volume extraction.
8. Proxy-Seller
Proxy-Seller provides a fundamentally different approach to data mining proxy infrastructure. Instead of a rotating pool, you purchase individual dedicated IPs in specific locations and own them exclusively for the rental period.
For data mining, dedicated IPs solve a particular challenge. When your pipeline needs to maintain authenticated sessions, accumulate cookies, or build browsing history on targets that serve different content to new versus returning visitors, a dedicated IP provides that continuity. Buy 25 dedicated IPv4 addresses in your target markets. Each one maintains its session state, cookie jar, and behavioural history across your entire extraction schedule.
The 220+ locations cover markets that larger providers sometimes miss, including smaller European, Asian, and South American cities. Each IP includes unlimited bandwidth and supports HTTP and SOCKS5. Proxy-Seller fits data mining operations that extract from session-dependent targets where maintaining persistent identity improves data access and completeness.
Pipeline Integration
Cost Structure
Datacenter IPv4 from $1.39/IP monthly. ISP proxies by location. Daily rental available.
Pros
Cons
9. NetNut
NetNut differentiates through direct ISP connectivity that bypasses the peer-to-peer residential model entirely. For data mining, this architecture delivers more consistent response times because traffic routes through ISP backbone infrastructure rather than through a residential peer device that may be on WiFi, behind a congested router, or experiencing variable latency.
The 85 million+ residential pool with direct ISP connections covers 150+ countries. Static residential (ISP) proxies maintain persistent connections for extraction workflows that run against the same targets repeatedly over weeks or months.
The enterprise-focused positioning means dedicated account management and custom configurations for teams with complex extraction requirements. NetNut fits established data mining operations and enterprise analytics teams that prioritise connection stability and consistent throughput over raw pool size.
Pipeline Integration
Cost Structure
Residential from $6/GB entry tier. Enterprise pricing for volume. Use code AFFCOUPON20 for 20% off.
Pros
Cons
📈 Industry Shifts Reshaping Data Mining Proxy Needs in 2026
Several developments from the past year directly affect which proxy infrastructure data mining teams should invest in.
AI-driven anti-bot systems are winning. Cloudflare and DataDome now use machine learning to detect automated traffic based on mouse movement patterns, scroll velocity, and interaction timing. Standard residential proxy rotation is no longer enough for protected targets. Data mining teams increasingly need stealth browser capabilities (ZenRows, Thordata, Oxylabs) alongside IP rotation.
AI and ML integration drives tool demand. 65% of senior logistics executives report a technological shift after adopting AI, ML, and data mining tools. The data analytics market is growing at 28.7% CAGR toward $302 billion by 2030. More analytics demand means more raw web data needed, which means more proxy bandwidth consumed.
Cloud deployment dominates. Cloud captured 69.95% of data mining tool deployments in 2025 and is growing at 16.92% CAGR. Cloud-native data mining workflows need proxy providers that integrate with cloud storage (S3, GCS, Azure Blob). Oxylabs Result Aggregator and Bright Data's cloud delivery options address this directly.
Self-service scraper APIs replace custom scripts. Oxylabs, Decodo, Thordata, and Bright Data all launched or expanded scraper API products in 2025/2026. The trend is clear. Data mining is moving from “build your own scraper and route through proxies” toward “call an API and receive structured data.”
✅Choosing the Right Mining Infrastructure
1. Request Volume and Cost Model
Data mining generates enormous request volumes. A product catalogue extraction across 500,000 pages using Scrapy could consume 100 to 500 GB of bandwidth in a single run. At $5/GB, that is $500 to $2,500 per extraction cycle. At Thordata's unlimited model, it becomes a fixed monthly cost regardless of volume. Map your expected monthly bandwidth consumption before choosing a pricing model. Unlimited plans pay off above roughly 200 GB/month.
2. Target Protection Level
Match your proxy type to your target's anti-bot sophistication. Public government databases and academic archives work fine with datacenter proxies. Major ecommerce platforms need residential. Cloudflare Enterprise or DataDome-protected sites may require ZenRows or Oxylabs anti-bot stack. Running a test extraction against your top 10 targets before committing to a provider saves months of frustration.
3. Structured Output vs Raw Access
Decide whether you need raw HTML or structured data. If your team has engineers maintaining custom parsers, raw residential proxies from IPRoyal or Webshare at $1.75/GB provide the best economics. If parser maintenance drains engineering hours, scraper APIs from Decodo ($49/month), Oxylabs ($49/month), or Thordata handle parsing, anti-bot bypass, and delivery in one layer.
4. Geographic Distribution
Data mining that extracts geo-specific content (localised pricing, regional inventory, location-based search results) needs proxies in those exact locations. Oxylabs offers coordinate-level targeting. Decodo and Bright Data provide ZIP code targeting. For country-level extraction, most providers on this list deliver solid global coverage.
5. Pipeline Integration and Delivery
Consider how extracted data reaches your analytics stack. Oxylabs Result Aggregator delivers to S3 and GCS automatically. Bright Data supports cloud storage delivery on dataset purchases. Decodo outputs in JSON, HTML, Markdown, and table format. If your pipeline expects data in a specific format or location, choose the provider whose delivery matches your stack.
More Guides On Proxy Dime
🎯Final Thoughts
The right proxy for data mining depends on your extraction volume, target protection levels, and whether you want raw IPs or structured API output. Decodo and Oxylabs deliver the strongest scraper API stacks for teams that want structured data without building custom parsers.
Thordata makes high-volume continuous extraction affordable with unlimited bandwidth. IPRoyal's non-expiring model suits batch extraction workflows with irregular schedules.
Test before you commit. Decodo's free trial, Oxylabs 2,000-result trial, and Thordata's no-credit-card evaluation let you validate success rates against your actual targets. The proxy that works on someone else's target may not work on yours. Run the extraction. Check the data completeness. Then decide.





